|
并行处理在性能方面可能是一个大问题。现代计算机具有多个内核,并且这些内核上的扩展过程充分利用了可用的计算能力。 FME通过定义多个流程的参数来利用它们。此外并行处理的转换器也有一个“输入是否有序”的参数,这是另一个性能增强工具。 此外......我们看到支持案例和测试结果表明我们应该重新设计并行处理设置; 所以对于FME 2019来说,这正是我们所做的! 
并行处理如何在2019版本发生变化简而言之,我们从FME 2019中的所有单个转换器中删除了并行处理选项: 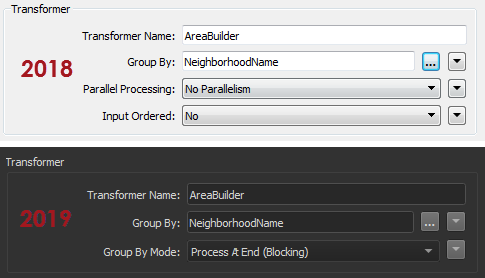
请注意,现在没有并行处理参数(此外输入是否有序参数现在是按模式分组)。但别担心!并行处理仍然可用。只是现在它作为了自定义转换器的选项了。 如果您对我们进行更改的原因不感兴趣,请跳到下面的“FME 2019和并行处理”。 但如果你想知道原因,继续阅读......
FME2019之前并行处理的问题并行处理很复杂。也许比我们的界面更复杂。用户需要计划要创建的进程数以及每个进程要处理的要素数。此外还有一些复杂的要素(在并行处理时可能会发生变化)。 简而言之,在FME2018中,我们认为用户降低工作空间的效率可能性更大,而不是加快速度。这有几个原因...... 界面设计在设计方面,并行处理的复杂性因其参数的突出而变得复杂。我们最后意识到该功能应该不会出现在每个转换器对话框的顶部!有点令人困惑,它与转换器的核心目的无关。 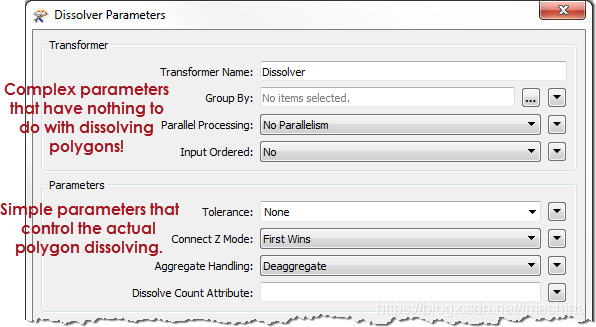
想象一下,如果你的电视遥控器上的最大按钮是用于微调图片颜色!这就是将并行处理转移到不太明显的地方的一个原因。复杂性和突出性的混合导致了错误使用并行处理。最常见的错误是进程数量...... 多个并行处理您可能知道,启动和停止FME进程会产生开销。将数据从一个进程传递到另一个进程也存在开销。因此,过多的进程会减慢转换速度,理想的情况是减少进程,处理更多要素。当有大量小作业时,额外开销大于并行处理的收益。整体转换速度较慢,而不是更快。 在FME2018中采用此示例工作区: 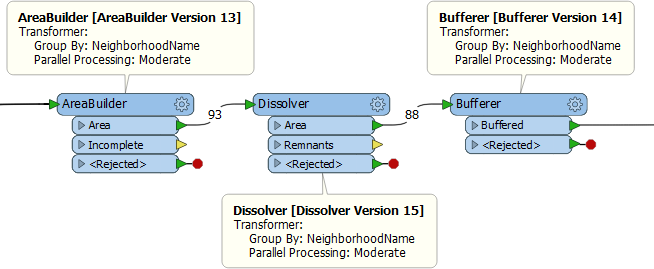
让我们从破除神话开始吧。您可能会认为,因为三个转换器都设置为并行处理数据,所以它们可能同时启动多个进程,使计算机瘫痪。事实并非如此。在所有AreaBuilder进程完成之前,Dissolver不会启动任何进程。因此,进程数量不会失控。 非常好。 但是,三个转换器都以同一属性分组! 假设有8个社区。每个转换器将创建8个进程。我们知道工作空间不会同时运行24个进程。但是,它总共将运行24个进程。但是实际上并不需要,因为每个转换器的组都是相同的!它可以在8个进程中完成相同的工作。 正如我稍后将演示的那样,如果模板编辑者将其变为自定义变换器并应用并行处理,那么将会有更少的进程。所以,这是我们改变的另一个原因。新设计鼓励正确的行为,因此模板编辑者更有可能做正确的事情,即使他们不知道它! 非平行转换器使用自定义转换器并行处理的另一个好处是,它可以并行化所有转换器,无论它们是否基于组。举个例子,让我们把Tester转换器放到前面的例子中: 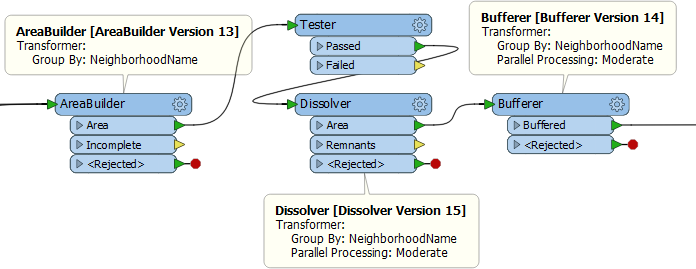
通过这种布局,AreaBuilder的8个进程然后汇聚回Tester的单个进程。然后将它们分为8个Dissolver进程。除了停止/启动过程之外,测试仪效率低,因为它是一个单一的进程。 如果这是在自定义转换器中创建的,那么并行处理也适用于Tester,这使其更有效。 输入是否有序和并行处理输入是否有序Input Ordered参数,因为是直接与并行处理,无论是在我们的代码还是参数对话框相邻参数: 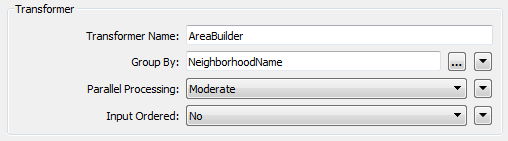
因为它在同一个参数分组块中,看起来是相关的。事实上并非如此。至少它们的相关性在于它们都与性能有关; 但是没有理由要求您的数据使用并行处理,或者必须并行处理有序数据。 因此,我们将这两个参数解耦以减少混淆,并防止用户错误地应用它们。特别是输入参数有序还控制什么是分组处理,因此不滥用它,它是特别重要的。它还重命名了新选项名称,使其更清晰: 
这就是我们做出这些改变的原因。现在让我们看看FME2019中的并行处理是什么样的......
FME 2019和并行处理FME 2019中的并行处理现在仅限于自定义转换器。这不是一项新功能。始终可以用这种方式并行处理数据。但是由于上述原因,这是并行处理数据的唯一方法。 我们来看前面的例子,现在是2019版本: 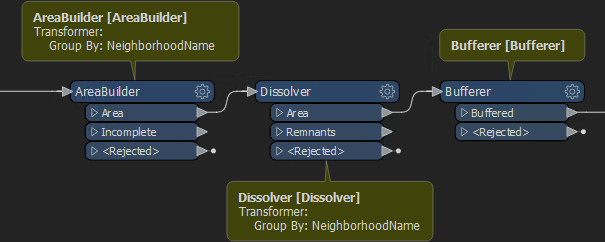
显然,不再有并行处理选项。因此,我将其转换为自定义转换器并在其参数中设置并行处理: 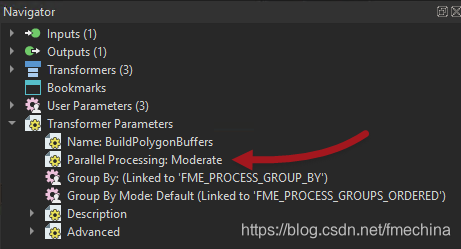
请注意,打开并行处理会自动添加Group-By发布的参数(如果没有组来划分数据,则无法进行并行处理)。所以我返回主画布,打开参数对话框,并将Group By参数设置为NeighborhoodName: 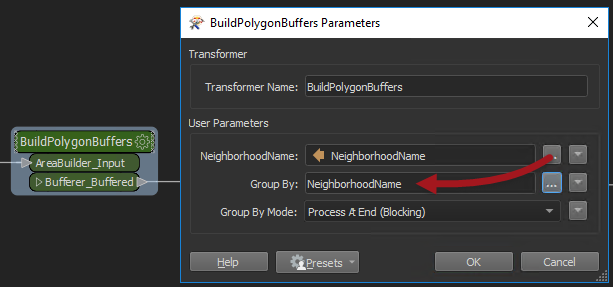
现在,当工作空间运行时,每个组都有一个单独的进程。但是,重要的是,每个进程都涵盖了三个转换器,因此启动的进程更少。 另外,如果我们添加一个额外的转换器 - 就像这个tester...... 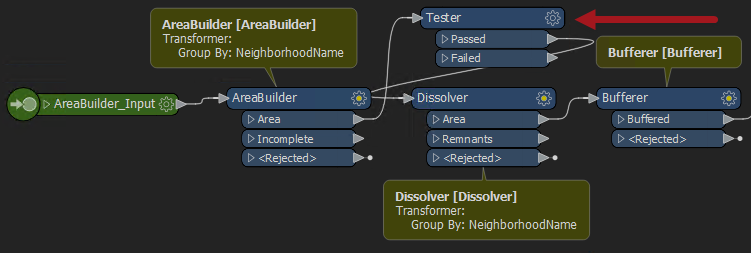
......它也是并行运行,这是一个额外的好处。 当然,你不需要非常注意注意到NeighborhoodName在变换器对话框中出现两次: 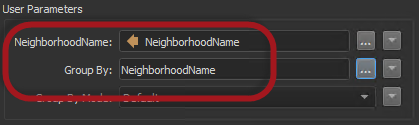
这是为什么? 不必要的用户参数回想一下,FME会自动发布Custom Transformer(自定义转化器)中使用的所有属性。这允许转换器在多个地方使用,其中(在此示例中)“NeighborhoodName”可能不可用。因此,FME在创建自定义转换器时自动生成这些已发布参数中的第一个,并且在激活并行处理时自动生成第二个参数。 我们需要他们吗?嗯,这取决于我在哪里使用NeighborhoodName。我可以从Group-By参数中删除对它的任何引用,因为整个自定义转换器现在是一个大的group-by。如果我在其他地方没有使用NeighborhoodName,是的,我可以删除第一个发布的参数。我不需要使用它。 但是,如果 - 例如 - 我在Tester转换器中使用NeighborhoodName,那么我可能想要保留第一个发布的参数。第一个提示我输入要测试的属性,第二个提示我输入要分组的属性。 在这里,我将删除使用自定义转换器创建的参数。 首先,我在每个转换器中取消设置Group-By参数。然后我删除用户参数;不是通过删除参数本身,而是从输入端口取消选中该属性: 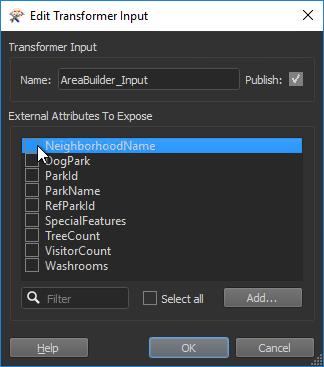
这会隐藏属性并且 - 不再需要 - 也会自动删除已发布的参数。 如果我以这种方式删除属性引用,那么我应该检查自定义转换器以查看是否有任何参数被标记为不完整(变为红色)。这表明我在某个尚未处理的地方使用了该属性。
常问问题问)如果我想将并行处理应用于单个转换器怎么办?
A)要将并行处理应用于单个转换器,您需要将其包装在自定义变换器中。这有点不方便,但我们认为总体设置更好。 | 问)如果我想将并行处理应用于自定义转换器内的单个转换器怎么办?
A)要将并行处理应用于自定义转换器内的单个转换器,您可以将其封装在自己的自定义转换器中。请记住,您可以将自定义转换器嵌套在一起。 | 问)如果多个转换器需要并行处理但具有不同的分组?
A)如果多个转换器需要并行处理,但具有不同的组,则将每个部分封装在单独的自定义转换器中。 | 问)我发现一个单独的转换器仍然存在并行处理参数。它为什么还在那里?
A)我们的更新比仅从GUI中删除参数更复杂,而且还有一些我们尚未更新的转换器。以后的FME版本可能会排除参数,因此我们仍建议在所有情况下使用自定义转换器方法。 |
摘要简而言之,这里的重要问题是绩效。工作空间作者总是希望获得性能优势,使用并行处理是一种明显的方法。不幸的是,这有点太明显了。我们认为新用户可以 - 试图加快转换速度 - 实际上减缓了他们的速度。 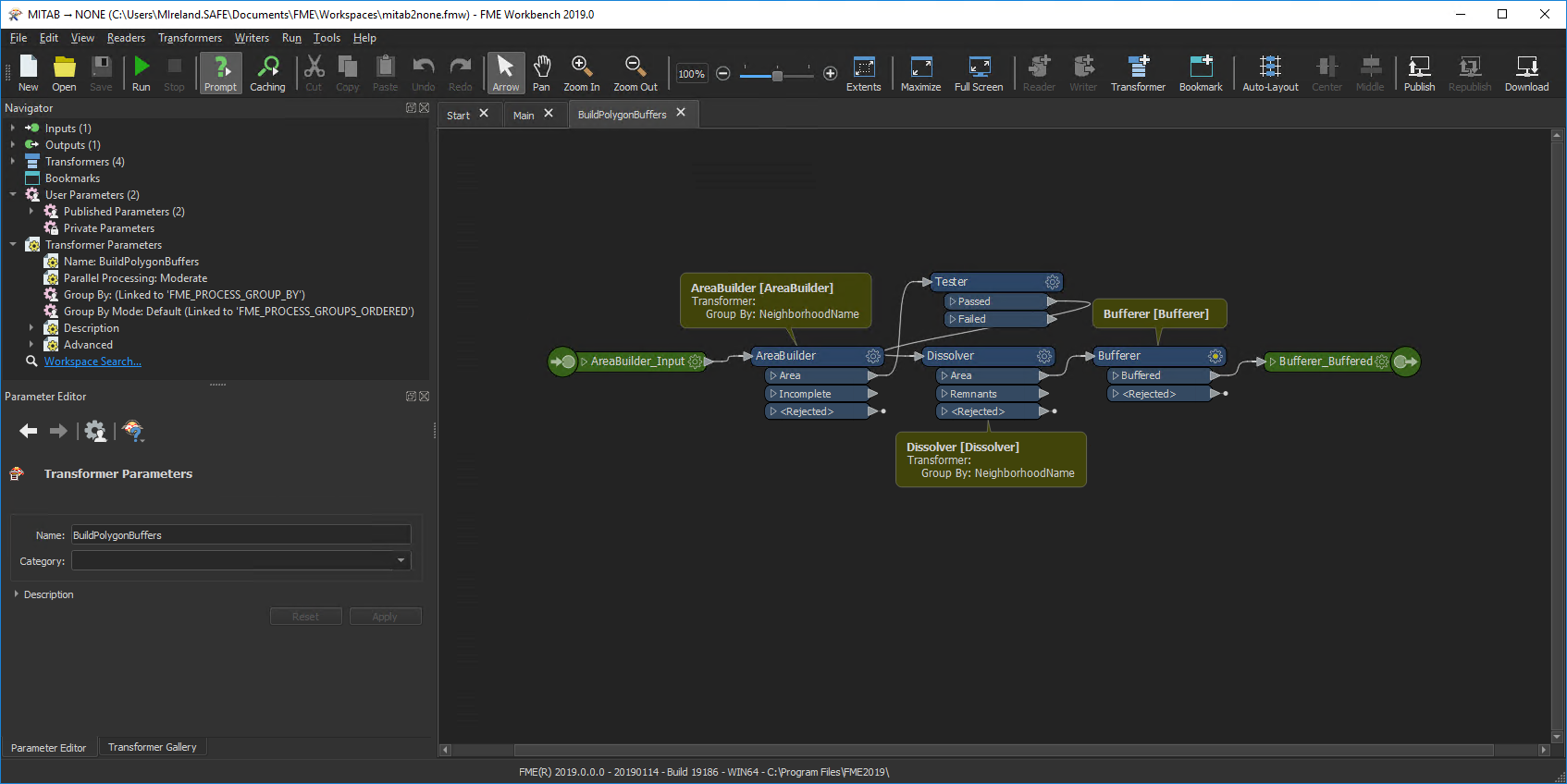
这就是为什么我们将并行处理参数移动到一个自然表现更好的地方。 顺便提一下,您可能已经注意到FME2019的上述屏幕截图处于“暗模式”。这只是我们希望您在即将发布的版本中享受的其他有用更新之一。 本文转载来自CSDN作者:fmechina 版权归作者所有 原文链接:https://blog.csdn.net/fmechina/article/details/86702003?spm=1001.2014.3001.5501 | 




 雷达卡
雷达卡




.gif)

 发表于 2021-5-25 15:32
发表于 2021-5-25 15:32
 提升卡
提升卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 显身卡
显身卡


