|
文内模板下载链接 https://pan.baidu.com/s/1FADN2Jb2cicCLEMZYD8DYA 提取码:2021
前言 本文是五篇系列文章中的第四篇,主要介绍了如何在FME Workbench中使用PythonCaller转换器,并且分别列举了不同应用情景下使用函数或类的PythonCaller转换器的的三个示例。 介绍 除了脚本化参数外,FME中还提供了PythonCaller转换器同样可以通过编写Python脚本对要素或要素组进行操作。当然,通常情况下FME中的转换器已经足够我们完成我们想要的任务功能,所以一般情况下,我们建议优先使用FME自带的转换器,当确实没有转换器可以完成要执行的任务时再考虑使用PythonCaller转换器。 让我们来简单了解一下PythonCaller转换器。首先,PythonCaller转换器可以调用函数,您可以直接使用它来处理某一要素,也可以在一个类中调用该功能,以对一组要素进行处理。此外,PythonCaller可以使用完整的FME对象,包括许多方法和类。 PythonCaller可以通过两种不同的方式与Python脚本对接,一种是通过函数,一种是通过类。当我们打算一次处理一个要素时,请使用函数接口,而使用类接口可以提升程序处理的灵活性。 FME对象和Python 通过使用FME Objects Python API中的FME类和方法,可以在Python脚本中使用FME的许多核心功能。 示例1: 通过Python函数给要素添加属性 (示例模板:PythonCaller1.fmw) 同所有转换器一样,FME Workbench在“参数编辑器”窗口中包含了用于特定转换器的帮助按钮。在这里,我们将尝试使用帮助文档里“函数接口示例”部分下(如下图)包含的一部分示例代码为要素添加时间戳。当然,这并不是PythonCaller的理想用法,因为我们完全可以使用FME已有的 DateTimeStamper转换器完成此任务。不过,这确实可以简单直观地演示如何使用PythonCaller转换器。 这里您可以使用该示例代码通过创建自己的工作空间来进行练习,也可以查看我们提供地示例模板(PythonCaller1.fmw)来进行演示练习。 
PythonCaller转换器帮助文档中的PythonCaller函数接口示例
下面让我们来具体实现一下。首先,让我们来找一下PythonCaller转换器的脚本编辑器。我们需要将PythonCaller转换器添加到我们的工作空间中并双击它。这时我们就可以看到位于弹出窗口左下方的“参数编辑器”按钮了,如果没有找到它,我们也可以从菜单栏中“视图”>“ Windows”>“参数编辑器”中将其打开(如下图)。 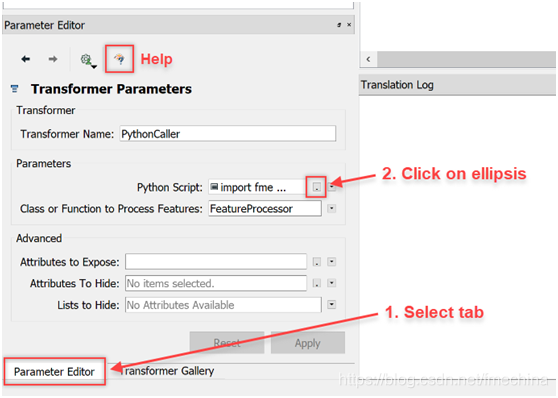
有关如何访问PythonCaller的Python脚本编辑器窗口的说明
接下来,单击如上图所示的“ Python脚本”参数右边的省略号以打开代码编辑器。需要注意的是,代码编辑器里已经有一个模板函数和类了,所以我们需要删除类模板,因为我们现在仅想使用一个函数。然后我们需要重命名函数为timestampFeature,并从PythonCaller帮助页面“函数接口示例”部分或下面的代码中复制代码到代码编辑器里。您可能需要在代码中添加一些换行符和缩进,使它看起来像下面这张图这样。(注意,缩进在Python中很重要): 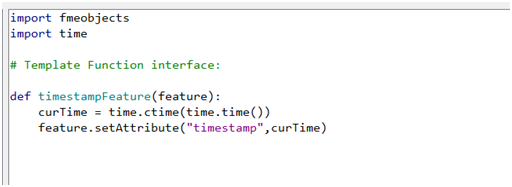
下面我们来分析一下这几行代码。首先,由于该脚本使用FME Objects方法,因此我们需要引入fmeobjects,此外由于我们正在使用Python time模块,因此我们还需要引入time。接下来,函数定义接受FMEFeature对象作为其唯一参数,这意味着所有特征都将一个接一个地输入函数进行处理。 在使用功能上,setAttribute()方法将添加新属性到要素,这是FME Objects方法之一。最后,单击确定以关闭代码编辑器即可。 然后,在同一窗口中,我们需要将“类或函数以处理要素”参数设置为函数的名称:timestampFeature(如下图)。 
此外,因为我们添加了一个名为“timestamp”的新属性,所以我们可以通过在“暴露的属性”参数中输入其名称来公开它。而要显示新属性,请双击该字段或单击省略号,然后在“输入要公开的属性的值”窗口中键入新的属性名称(如下图)。 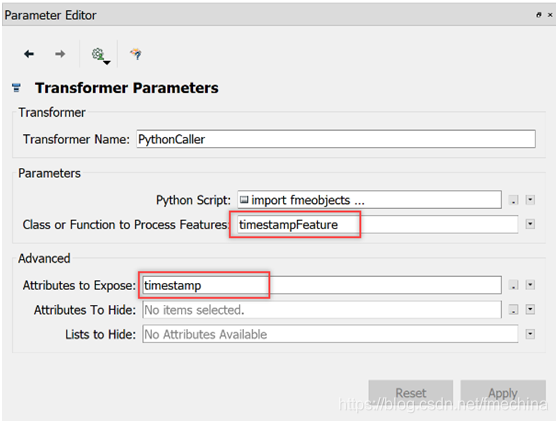
完成代码的编写以及转换器的设置后,让我们使用Creator转换器创建一些要发送到PythonCaller的要素,并运行该模板。模板运行完成后,转到运行工作空间查看“转换日志”窗口,可以看到每个要素都具有了新的时间戳(timestamp)属性。 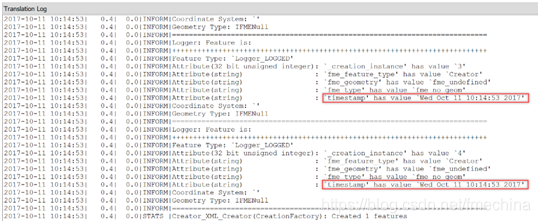
在“转换日志”窗口中的查看添加到每个要素的属性 示例2:FuzzyStringComparer自定义转换器的Python函数 (示例模板:PythonCaller2.fmw) 在FME Hub上发布了一个名为FuzzyStringComparer的自定义转换器,该转换器使用Python difflib模块来比较两个字符串属性并计算相似率。某种程度上,这是一个相比于示例1更好的示例,因为这是常规FME转换器无法做到的,该自定义转换器的使用您可以查看我们提供的示例模板PythonCaller2.fmwt。 下面让我们来具体演示一下该自定义转换器。首先,打开一个空白工作区,并为我们的数据添加一个读模块。之后,添加一个AttributeManager为之后的相似率创建一个新属性(如下图)。 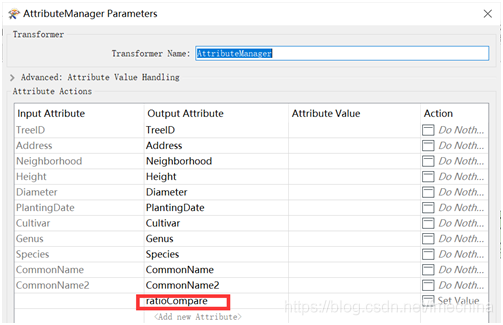
接下来,提供通过在工作空间空白处键入转换器名称或通过在“转换器库”窗口(如下图)中浏览FME Hub来查找FME Hub转换器FuzzyStringComparer,并将其添加到工作空间。 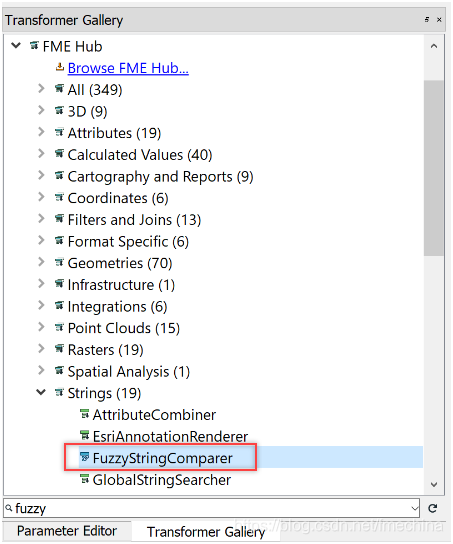
添加好自定义转换器后,双击该转换器,在弹出窗口中(如下图),选择我们要比较的两个字符串属性,然后输入存储相似率属性的名称,该名称应与我们刚刚使用AttributeManager创建的新属性名称相匹配,这就完成了该自定义转换器的使用设置。 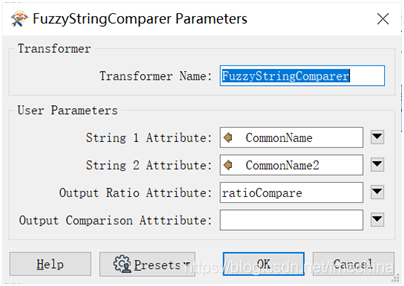
那么FuzzyStringComparer转换器是如何实现比较属性功能的呢?让我们选择该转换器,右键单击它,然后选择“编辑”以查看其内容。这时,一个新的工作空间选项卡将打开(如下图)。 
让我们找到PythonCaller转换器,然后转到其属性以访问脚本编辑器查看代码内容。以下代码可能看起来很复杂,但是此示例与第一个示例相似。就本示例而言,我们将仅关注相关核心代码的各个部分,且值得注意的是,这里我们使用的依旧是一个函数,只是这次是逐个要素的比较字符串属性。脚本的总体思路为,使用feature.getAttribute()获得两个字符串属性,并将它们分别定义为string1和string2。而后,将字符串与difflib.SequenceMatcher类进行比较,并创建一个SequenceMatcher对象。之后再通过调用SequenceMatcher对象的ratio()方法,返回测量两个字符串相似度的比率。最后,我们为要素创建一个名为FuzzyStringCompare.ratio的新属性,并为其分配比率值即为我们最终的结果。
import difflib import sys
def FuzzyStringCompare(feature): # get strings from attributes string1 = feature.getAttribute('FuzzyStringCompare.string1') string2 = feature.getAttribute('FuzzyStringCompare.string2') version = sys.version_info[0]
if string1 != None and string2 != None: # convert to unicode strings if necessary if version > 2: if not isinstance(string1, str): string1 = '{}'.format(string1) if not isinstance(string2, str): string2 = '{}'.format(string2) else: if not isinstance(string1, unicode): string1 = u'{}'.format(string1) if not isinstance(string2, unicode): string2 = u'{}'.format(string2) # calculate difference ratio s = difflib.SequenceMatcher(None,string1.lower(),string2.lower()) ratio = s.ratio()
# update input strings differ = difflib.ndiff(string1,string2) diff1 = '' diff2 = '' for line in differ: if line[0] == '-': diff1 = diff1 + (line[2]) diff2 = diff2 + ' ' elif line[0] == '+': diff1 = diff1 + ' ' diff2 = diff2 + (line[2]) else: diff1 = diff1 + (line[2]) diff2 = diff2 + (line[2])
# set new attributes on feature feature.setAttribute('FuzzyStringCompare.ratio',ratio) feature.setAttribute('FuzzyStringCompare.string1',diff1) feature.setAttribute('FuzzyStringCompare.string2',diff2)
如同之前的示例一样,PythonCaller的参数对话框告诉PythonCaller转换器要调用的函数和要公开的属性。而由于这是一个自定义转换器,因此该字段将已经预先填充了“ FuzzyStringCompare”(函数名称)和属性“ FuzzyStringCompare.ratio ”(包含相似率的属性名称)。在PythonCaller转换器之后通过一个AttributeCreator获取新属性值,以便接下来的步骤中转化器可以访问其值。 完成设置后,连接Inspector并运行工作空间以查看输出。我们可以看到要素有了一个新的属性,其值的范围从0到1.0,代表我们指定的两个字符串属性之间的相似率。 (注意:本文使用转换器版本为5,如果FuzzyStringComparer自定义转换器中的Python代码与上述代码不同,则您很可能已下载了不同版本的自定义转换器,但是,原理应大致相同。) 示例3:通过Python类计算所有要素面积 (示例模板:PythonCaller3.fmw) 示例3中,我们将再次使用转换器帮助页面中“Class Interface Example”部分中提供的PythonCaller示例代码(如下图)。与之前示例不同的是,这次我们将使用类而不是函数来计算所有要素的面积。虽然使用FME中已有的转换器完全可以轻松完成此任务,但是,在这里我们将向您展示如何使用Python来完成此过程。您可以自己搭建模板,也可以使用我们提供的示例模板PythonCaller3.fmw来完成演示。 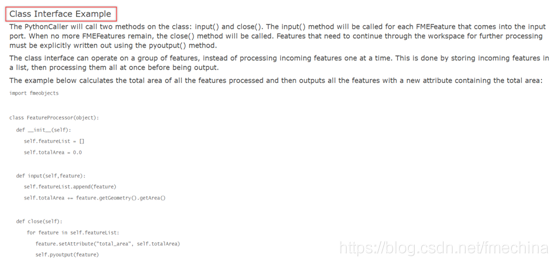
PythonCaller转换器帮助文档中的PythonCaller类接口示例 让我们来看一下示例模板的搭建流程和思路。首先,启动一个新的空白工作空间,并使用Creator转换器创建多边形要素(要创建多边形要素,请打开Creator参数,双击Geometry Object,选择Polygon,然后在Geometry Parameters下至少添加三个坐标即可)。之后,添加一个PythonCaller转换器并连接一个Logger以查看输出。 接下来让我们打开PythonCaller并在代码编辑器中打开脚本。您可能需要在代码中添加一些换行符和缩进,以便看起来像下图这样(注意:缩进在Python中很重要): 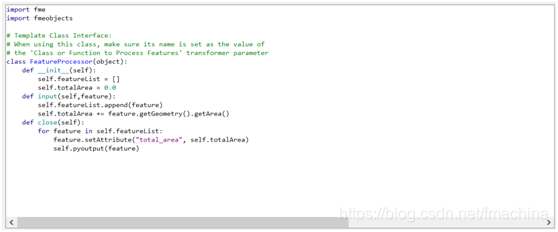
在该示例脚本中,我们同样使用了许多FME Objects方法,因此我们需要引入fmeobjects。输入要素方面,我们将每个要素添加到列表中,并从每个要素中获取面积添加到self.totalArea中。在close方法中,我们遍历表中每个要素,并创建新属性total_area,赋值为self.totalArea的值。这里需要注意的是,如果我们希望要素通过PythonCaller后继续传递到工作空间中,则必须使用pyoutput()方法将其写出。 完成代码编写后,单击“确定”关闭代码编辑器。在转换器中,需要将“Class or Function to Process Feature”设置为类的名称:FeatureProcessor。而由于我们添加了一个名为total_area的新属性,因此可以通过在“暴露的属性”参数中输入其名称来公开它(如下图)。 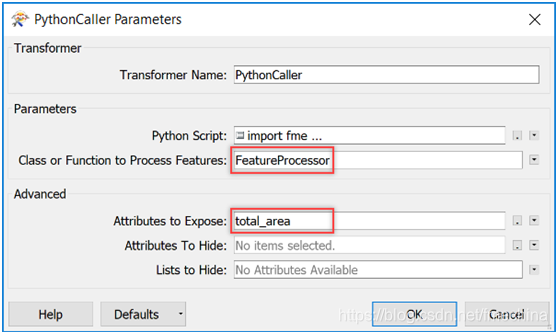
完成代码编写和转换器设置后,运行工作空间,以确保要素上具有total_area属性。之后打开Creator转换器,增加要素数量,再次运行工作空间以查看所有要素的总面积(如下图)。 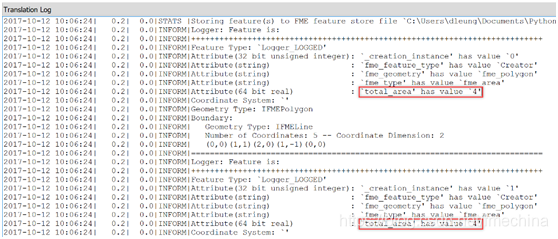
​​​​​​​示例4:通过Python类自定义KML文件夹层次结构 (示例模板:PythonCaller4.fmwt) KML转换教程中的“通过要素类型扇出创建KML文件夹”概述了创建KML文件夹的两种不同方法,它们定义了Google Earth Places窗口中的嵌套树结构。而其中所给的第二种方法(如下图)使用KML ID来定义自定义层次结构,并直接控制文件夹命名,继承关系和文件夹级别。 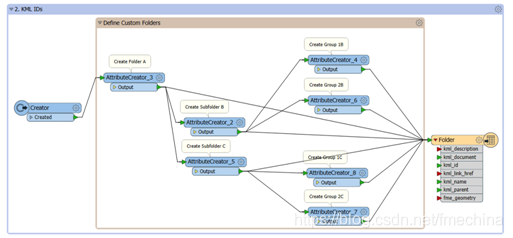
使用AttributeCreator为每个文件夹级别内的每个文件夹手动定义自定义文件夹层次结构 但是,使用Creator创建每个文件夹的空几何记录,并使用AttributeCreator或AttributeManager为每个文件夹设置kml_id,kml_parent和kml_document属性的操作既费时又费力。所以这里我们想通过使用一些简单的转换器准备数据以及一个PythonCaller转换器编写代码,来使该过程更加高效和自动化。这里您可以自己搭建模板或使用本文提供的示例模板PythonCaller4.fmwt。 下面让我们来看一下如何自动化高效实现这一示例。首先,让我们启动一个新的空白工作空间并添加一个写模块。这里我们的输入要素有两个数据流,一个数据流将编写包含几何的特征,第二个数据流将定义和创建KML文件夹。在此示例中,我们将专注于第二个数据流。 之后,添加GeometryRemover和AttributeManager转换器到工作空间中。这两个转换器的主要目的在于找到需要为每个级别创建的每个文件夹。而要查找第一级文件夹和第二级文件夹的每种可能组合,则需要我们在AttributeManager中的两个属性值之间用定界符创建第二级文件夹属性和第一级文件夹属性(示例工作区中的“犯罪类型”和“邻居”)的串联字符串(如下图)。 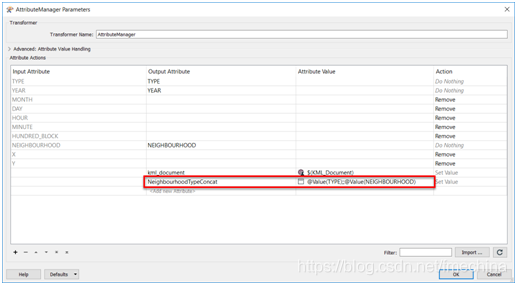
创建2级和1级文件夹属性的串联字符串值,并在两个值之间使用定界符 接下来,添加UniqueValueLogger自定义转换器,并将“Attribute to Analyze”参数设置为AttributeManager中创建的连接字符串值。该自定义转换器主要用于查找第二级和第一级属性(犯罪类型和邻域值)的所有唯一组合。再之后,添加一个PythonCaller转换器并编写脚本如下: 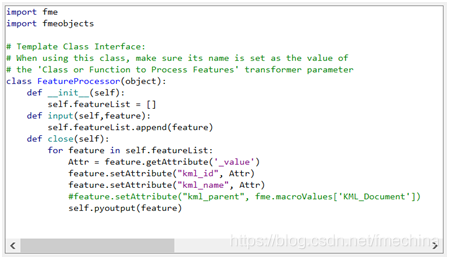
让我们来分析一下这些代码。首先,由于该脚本使用FME Object方法,所以这里我们需要引入fmeobjects模块。而后,该脚本在__init__函数中初始化一个列表,然后使用append方法将要素添加到输入函数中的此列表中。 接下来在close函数中,我们遍历要素列表,并使用getAttribute()方法获取每个要素_value值的串联字符串值(示例工作空间中的犯罪类型和邻域)。 为了确定要创建的文件夹的名称,我们使用kml_name属性。而在串联的字符串值上使用rpartition方法,在分隔符/定界符处分割要素(在示例中为';;'),并将第一个元素(称为listAttr.rpartition(';;')[0])设置为kml_name的值(犯罪类型)。(注意:使用第一个还是最后一个元素将取决于串联字符串的结构)。最后,通过运行检查输出要素,确保使用正确的值。 同样地,要确定父文件夹,我们使用kml_parent属性,使用最后一个元素[-1]代替使用rpartition的第一个元素。另外,由于每个文件夹要素必须具有唯一的ID值,因此我们将串联的第一级和第二级字符串值设置为kml_id。 由于我们需要为每个要素创建一个文件夹,因此我们需要使用self.pyoutput(feature)来确保空文件夹要素在整个工作空间中继续存在。这里需要注意地是,最后我们需要在PythonCaller中公开KML写模块所需的属性,例如kml_id,kml_name和kml_parent。 而对于一级文件夹则相对更简单一些,因为它仅需要一级属性的每个唯一值。在示例中,这是“邻居”值。这里同样地,我们使用UniqueValueLogger查找唯一的1级文件夹属性,使用上面类似的Python脚本,我们可以将唯一属性值设置为kml_id和kml_name,但是不必为一级文件夹设置kml_parent。 模板最后,为“Folder”要素类型添加一个KML写模块,并将PythonCallers的输出连接到该写模块。然后,此写模块将为您的要素创建自定义文件夹层次结构。到此,整个自动化过程也就设置完毕了(如下图)。 
为了将我们的要素(包含几何)与相应的父文件夹关联起来,需要创建一个kml_parent要素属性,并使用AttributeManager将其值设置为您希望要素所在文件夹的kml_id。在示例工作空间中,它是第二级文件夹属性和第一级文件夹属性值(完整工作空间中的@Value(Type);; @ Value(Neighbourhood))的连接字符串。这里,添加另一个KML要素类型写模块,并连接AttributeManager的输出(如下图)。 
使用kml_parent属性将功能与相应的父文件夹相关联的工作流程 运行工作区并在Google Earth中打开生成的KML文件。由于该文件已经创建了自定义文件夹层次结构,并且要素与父文件夹相关联,从而可以进行数据组织并易于查看(如下图)。 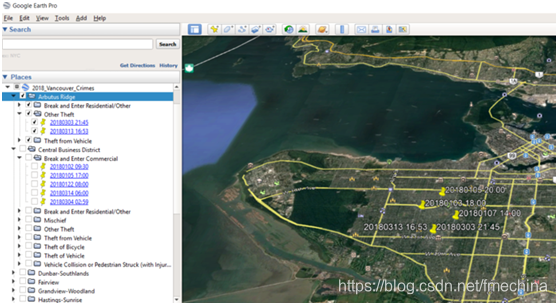
通过使用UniqueValueLogger自定义转换器和Python脚本的数据驱动过程创建的具有自定义KML文件夹层次结构的Google Earth中的数据视图 数据来源 此处使用的数据来自不列颠哥伦比亚省温哥华市提供的开放数据,它包含根据“开放政府许可证-温哥华”获得许可的信息。
本文转载来自CSDN作者:fmechina 版权归原作者所有 原文链接:https://blog.csdn.net/fmechina/article/details/115008921?spm=1001.2014.3001.5501
| 




 雷达卡
雷达卡




.gif)

 发表于 2021-3-22 14:34
发表于 2021-3-22 14:34
 提升卡
提升卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 显身卡
显身卡






