|
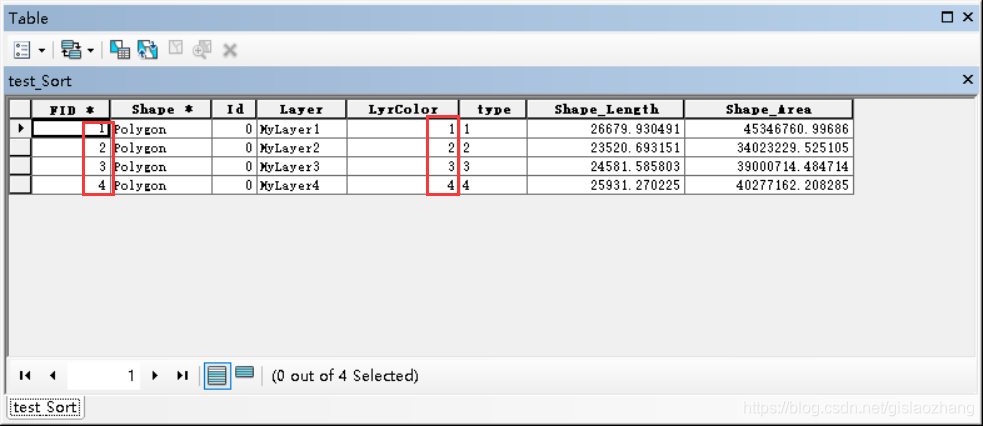
本篇博客将平时对arcgis属性表的相关操作记录下来,防止忘记。此外,在技术摸索中参考了一些gis大牛的博客和技术分享,我在博客结尾也粘贴了他们的博客地址在此表示感谢。 案例一:arcgis属性表某个字段自动编号。例如:从1开始往后自动编号。将下图中数据类型为文本型的typeid字段进行自动编号,数据记录从1开始往后递增。 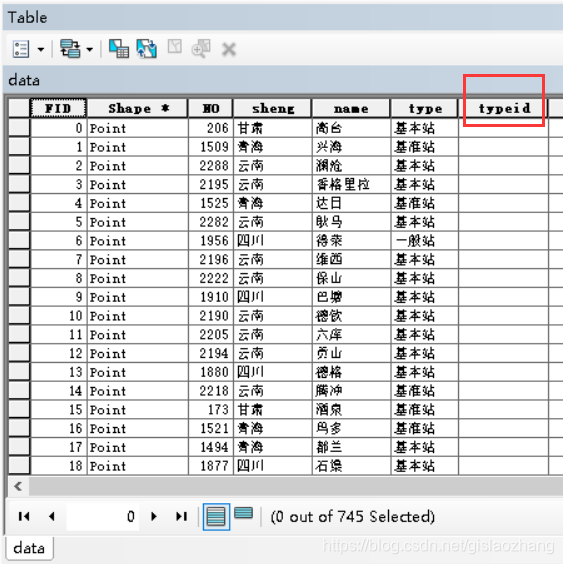
在该字段上右键,进入字段计算器,勾选“Python”; 在“预逻辑代码块”区域粘贴以下代码;
rec=-1
def autoIncrement():
global rec
pStart = 1 #起始值为1,可修改
pInterval = 1 #间隔值为1,可修改
if (rec ==-1):
rec = pStart
else:
rec = rec + pInterval
return rec
(上述代码含义:首先初始化rec为-1;接着定义一个autoIncrement方法,在这个方法里定义了一个局部变量rec,初始化pStart为1,它也是起始值,如果想typeid起始值为其它值可以修改pStart的值即可,pInterrval是间隔值,即依次递增的数字之间的间隔是1,如果想依次递增的数字之间的间隔是2或者3...等,可以修改pInterrval的值;再接着就是一个if()else语句,最后将rec进行返回。)
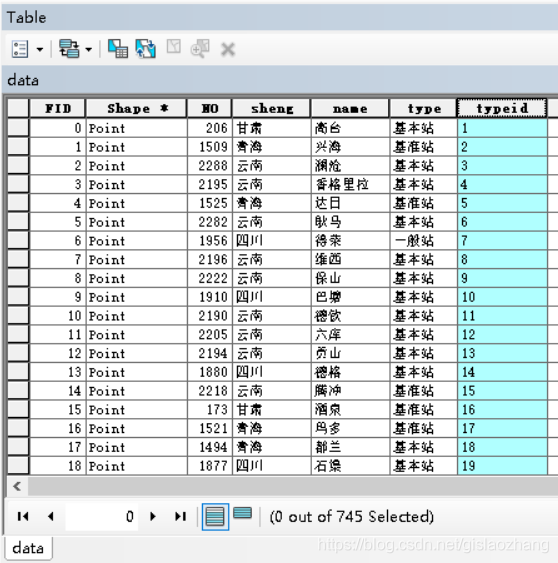
然后将autoIncrement()方法给typeid,最后点击“确定”运行。 (注意将autoIncrement()方法给typeid时,autoIncrement()方法前不能有空格,否则会报错!!!) 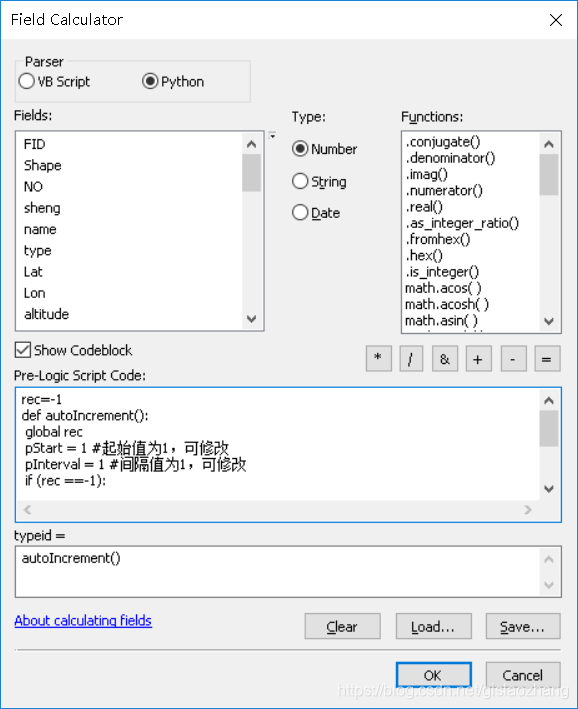
补充: 上述的案例是基于FID进行自动编号,如何根据其它字段进行自动编号呢? 思路:使用sort工具,基于某个字段进行编号,生成新的输出数据,然后基于新的输出数据使用案例1中的python代码进行自动编号。 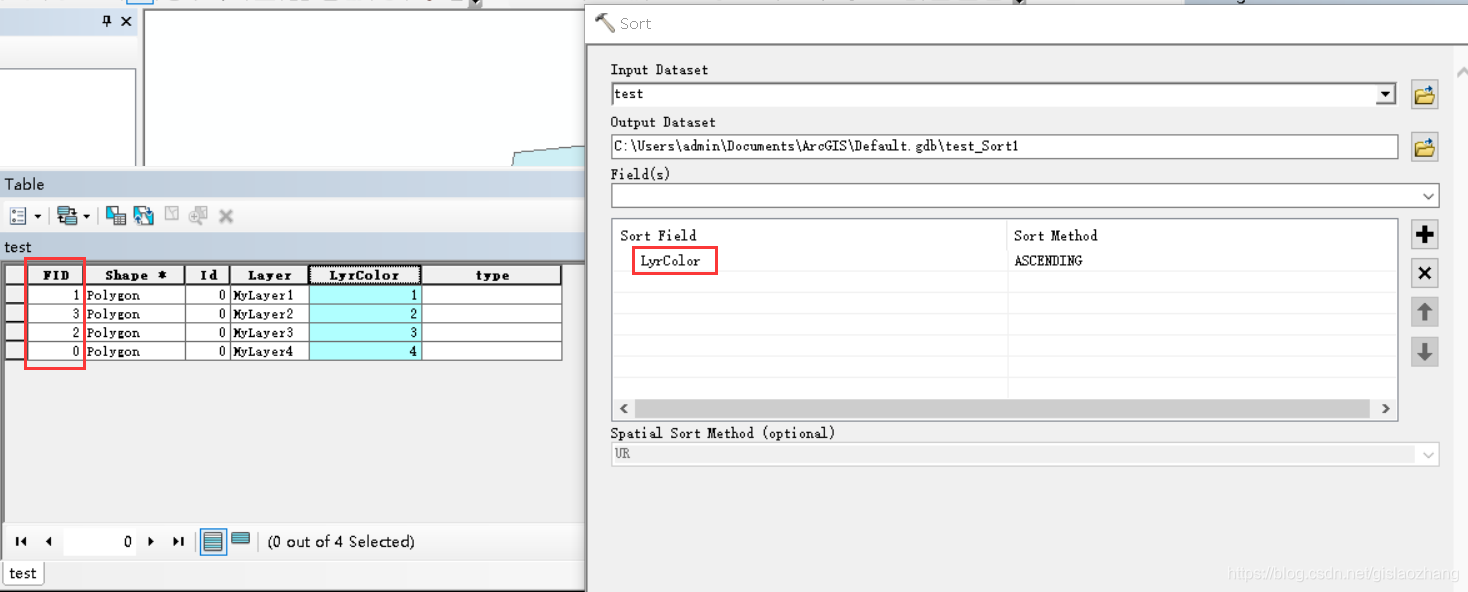
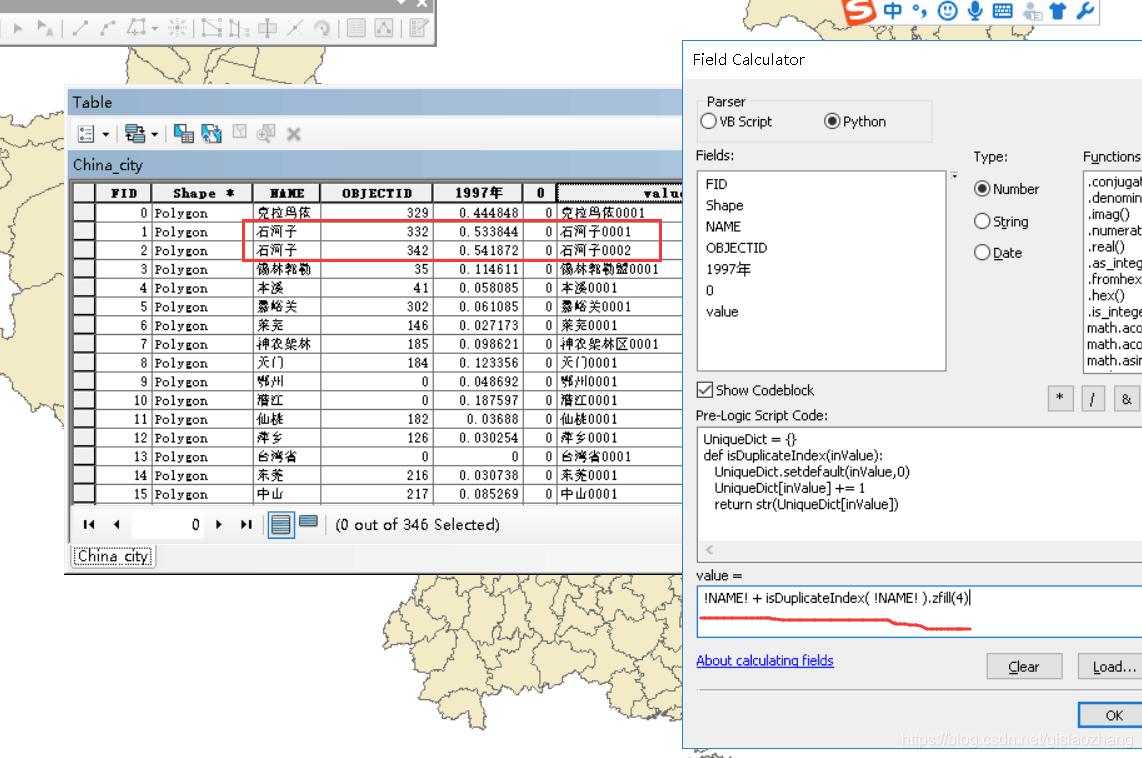
参考资料: http://www.cnblogs.com/liweis/p/4153333.html //使用Python给要素添加序号 案例二:对属性表中某一字段自动编号例如:属性表中的“县级”行政单位进行自动编号,存在县名称重复的情况,例如:A县有多次重复,那就按A0001、A0002、A0003自动编号,每个县都从0001开始编号。 python代码如下:
UniqueDict = {}
def isDuplicateIndex(inValue):
UniqueDict.setdefault(inValue,0)
UniqueDict[inValue] += 1
return str(UniqueDict[inValue])
字段中写: isDuplicateIndex( !NAME! ).zfill(4)
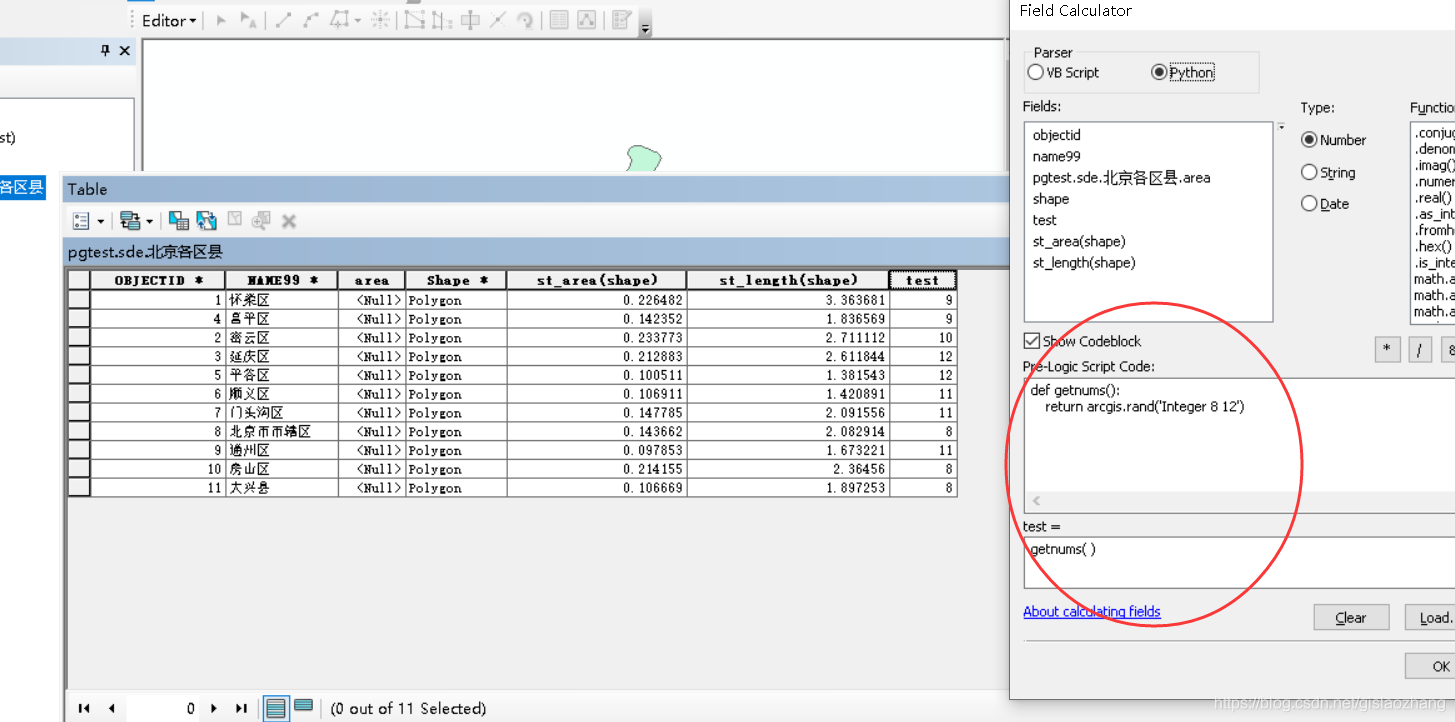
 案例三:arcmap或者arcgispro在某字段中生成随机数 案例三:arcmap或者arcgispro在某字段中生成随机数例如:对整型字段随机生成8-12范围内的数字 如果是在arcmap中操作的话,可以使用下述脚本 参考资料:https://desktop.arcgis.com/zh-cn/arcmap/10.3/tools/data-management-toolbox/calculate-field.htm
def getnums():
return arcgis.rand('Integer 8 12')
由于 
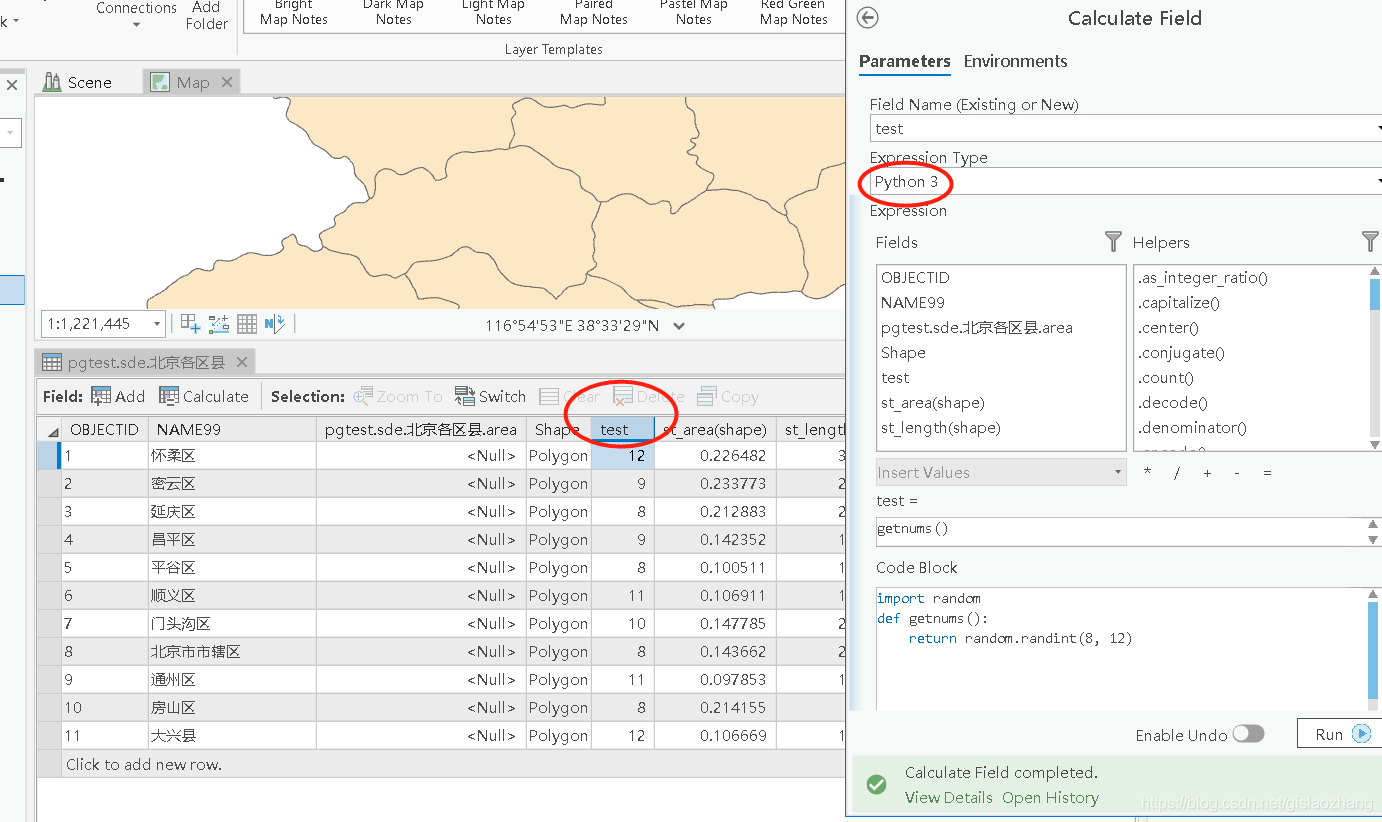
https://pro.arcgis.com/zh-cn/pro-app/tool-reference/modelbuilder-toolbox/calculate-value.htm 此时,如果要在arcgispro操作的话,可以考虑使用下述脚本
import random
def getnums():
return random.randint(8, 12)
案例四:查出省级行政区划名称(Chinese_Ch)为山开头,面积(Shape_Area)大于8000000的记录。查询文本框输入:
"Chinese_Ch" LIKE '山%' AND "Shape_Area" >8000000 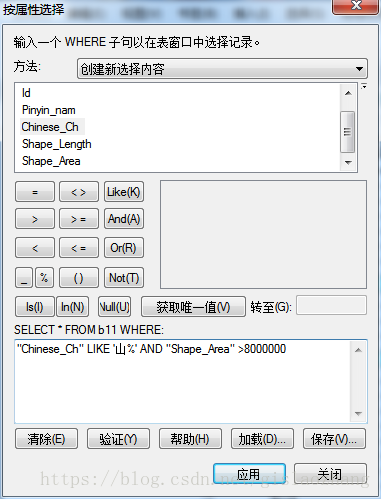
一般查询过程是在字段名称选择区中双击字段名、再选运算符,建立查询条件,并用Like、
And、Or、Not将几个条件组合起来。在设置字段的查询条件时,可在取值区中用鼠标选取,也可直接键入属性值。
字符型字段还可使用通配符,如用“%”替代多个字符,用“_”替代一个字符。例如:
"NAME"LIKE'张%'表示查询NAME字段,第一个字符为"张",不管后续有几个字符。
"LANDUSE"LIKE'F_'表示查询LANDUSE字段,第一个字符"F",第二个字符任意,但后续只能有一个。
按属性选择记录会出现语法错误,软件提示不能完成操作,引号、括号不匹配是常见差错,以下是注意事项:
(1)字符型操作不能用等号代替LIKE;
(2)字段名自身带双引号,如"LANDUSE",字符型取值用单引号,如'C',数字型取值不带引号;
(3)单引号、双引号必须都用英文字符,不能用中英字符。
(4)多用鼠标,少用键盘,可避免语法差错; 案例五:查询属性表相同项首先数据要求是存放在个人地理数据库(mdb)中,如果不是,需要先导入进去。这是因为个人地理数据库对子查询支持更好。
如果这个字段名叫name,表名叫area,SQL可类似如下写:
[name] in (select [name] from area group by [name] having count([name]) > 1) 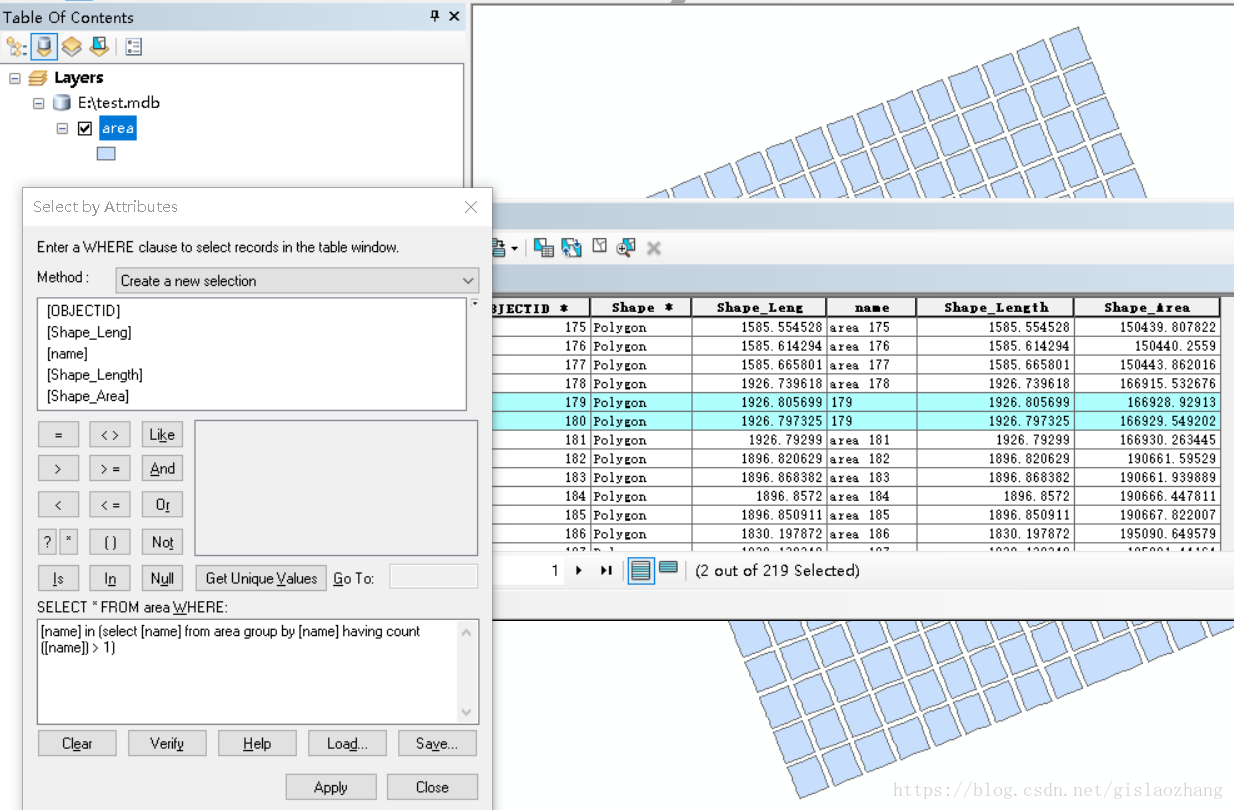
参考资料:
http://zhihu.esrichina.com.cn/question/6606 文件地理数据库对子查询提供了有限的支持,而个人地理数据库和 ArcSDE 地理数据库则提供完全支持,详情见链接介绍:http://resources.arcgis.com/zh-cn/help/main/10.2/index.html#/na/00s500000033000000/ 案例六:查询属性表中要素记录的长度例如:查询属性表中要素记录长度大于6的要素 CHAR_LENGTH(string_exp)
例如:查询字段名为‘名称’的长度大于6的要素
CHAR_LENGTH( 名称 ) >=6 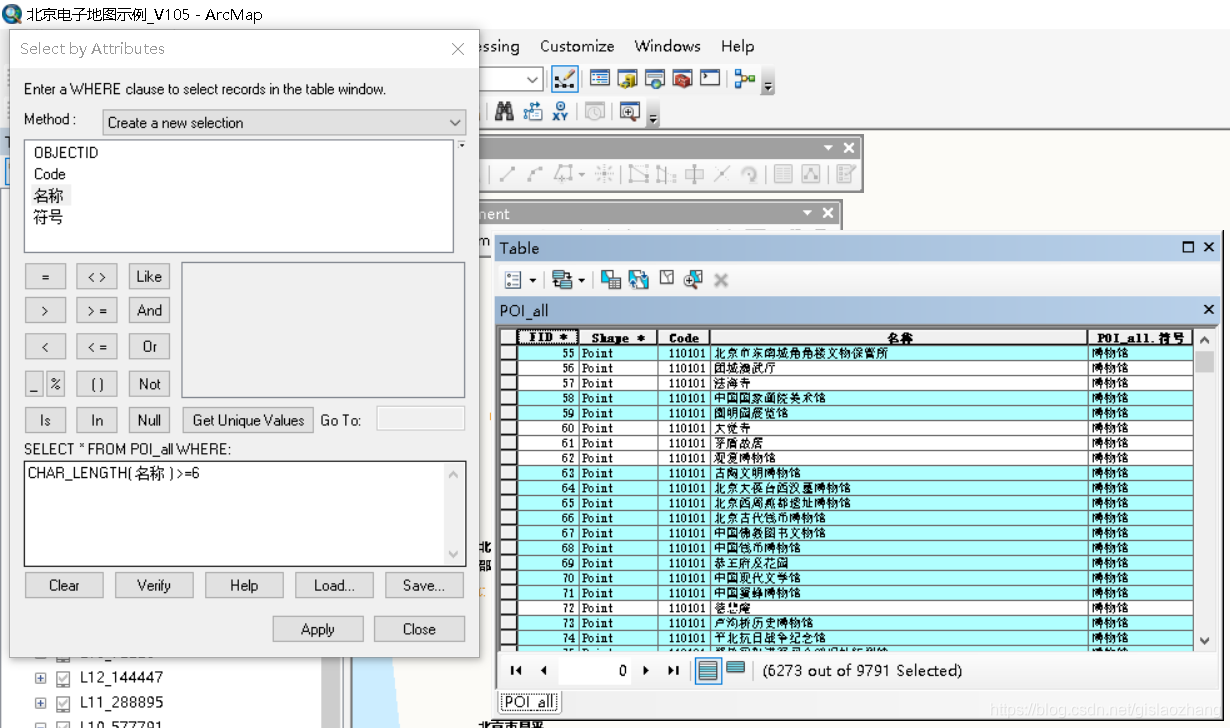
链接:http://resources.arcgis.com/zh-cn/help/main/10.2/index.html#/na/00s500000033000000/
案例七:对属性表中某一字段进行分段情景一:如何把一个shp文件批量均分为n个?比如:一个shp文件属性表共有10000个行,我想分为50组,200为1组,请问除了按属性选择,是否有批量直接分的方法? 参考资料:http://zhihu.esrichina.com.cn/question/34781 情景二:对某一字段进行分段求和,现有一个矢量图层,其中ACRES字段记录了每一个面要素的面积,如何分段对该字段求和,如该字段数值在以下范围时0-50,50-300,300-1000,>4000,其面积分别是多少? 参考资料:http://zhihu.esrichina.com.cn/article/2785
本文转载来自CSDN作者:gislaozhang 版权归作者所有 原文链接:https://blog.csdn.net/gislaozhang/article/details/77773947 | 




 雷达卡
雷达卡




.gif)

 发表于 2021-2-24 14:30
发表于 2021-2-24 14:30
 提升卡
提升卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 显身卡
显身卡
 发表于 2021-2-24 16:23
发表于 2021-2-24 16:23



