说实话,我还没有想好这个系列到底该怎么讲,今天下午粗略的想了下,我觉得程序都是靠代码来操作数据的,所以,我就起了这么个破标题。由于我本身水平实在是菜的可以,所以我理解的绝对不可能一点错误没有,只希望能通过我写的这些文字让更多的入门编程这个精彩的世界,倘若读者发现我写的有错误的地方,一定要回帖告知我改之,以免误人子弟,再次谢过。
先说一下这篇文字主要内容。
什么是数据及其在电脑中的存储方式。 数据类型 —— 区分数据的唯一指标。 变量的定义和使用方法。 - 结束语。
下面开始进入正题。
一、什么是数据及其在电脑中的存储方式。
学过计算机基础知识的朋友,尤其是学过编程的朋友,一定知道,现在的CPU是只认识二进制数据的,也只能进行二进制的数值运算,在实际操作中,由于二进制太过烦琐,而且容易失误,外加上十六进制与二进制之间在转换有很多的方便,所以一般的用十六进制表示其二进制数值:因此,我们看到的一些编辑器,调试器等分析出来的机器码都是十六进制的。(事无巨细,如果不明白十六进制、十进制、二进制等概念的朋友,请自行百度“进制转换”和“原反补码”)
1.什么是数据。
好现在让我们开下OD,看看下它分析出来的数据是什么模样:

如果你细心观察,就会发现,OD的数据视图中,用一些虚竖线,将这些数据每4个一组分割开了,如上图。
让我们再看下通用寄存器、看堆栈,如下图:

也都是4个一组,为什么呢?
现在主流的 操作系统 如(X86 XPSP6 等OS)都是32位的操作系统,这些操作系统在32位的硬件环境下,能够直接处理32位的数据,而且,数据以32位的单位对齐运行速度也是最快的,如果大家熟悉各进制之间转换的话,应该知道,十六进制与二进制之间的转换格式是1比4,就是说,1位十六进制的数能代表4位二进制的数据,(0xFF 就是 就是二进制的 1111),四位十六进制的数就是32位了!
2.数据在电脑中的存储方式
这些数据在存放到内存里的时候,有两种存放方式,学名字叫:Big Endian 和 Little Endian 。
这两个存取方式决定了内存存放数据的原则是高高低低 原则 还是 高低低高 原则,比如:我有一个数据,是0xA5A1,它在存放到内存中是怎样存放的呢?如果存成A5A1那就是高高低低存放的,如上图选中的部分,因为在我们平时的书写中,A5是高位,A1在低位,存放到内存中的时候,如上图,A1存放在00438400这个位置,而A5存放在00438401这个位置,高位存放在内存的高地址中,低位存放在低地址中,这种方式就是Little Endian,另一种方式就是Big Endian,现在绝大多数都是使用Little Endian 方式存放的(至今我还没有见到过Big Endian方式存数的数据。),如上图中大家看到的A1A50000这个数据,其实它的真实的内容是:0x0000A5A1。
到这里大家可能有个疑问:如果我要存一堆小的数据,每个数据都在内存里占4个字节的位置,是不是太占资源了啊!再说,如果我要存放的一个数据远大于0xFFFFFFFF,怎么办啊,如果我要存放的数据是:0x0089D8F4D326849A,在内存是会是什么样子呢?如下图:

如果我们按照我们刚才的分析方法,这个64位的大数就被分成了两个数:0xD326849A和0x0089D8F4 这显然是错误的,那我们怎么来表示,怎么才能不让程序读一个错误的数据出来呢?那就要提前规定好数据的大小。
二、数据类型 —— 区分数据的唯一指标。
通过上一章节的讲解,我们知道,要想完整的读取出一个数据,必须提前知道这个数据的大小。那么我们怎么知道或者怎么规定一个数据的大小呢?本小节就来解决这个问题。
1.什么是数据类型。
在日常生活中,我们经常把一些物品,事物归类处理,由此我们可以大概的猜测出来数据类型它的作用是什么。
数据类型的作用就是让程序知道自己要从内存里读多大的一个数据出来!比如上图中的大数,我可以只读一个0x9A出来,也可以读0x849A等等。
如果大家有看过编程相关的书,那一定看到过什么整型,字符型,逻辑布尔型,数组,结构体类型,等等一大堆!再什么时候该用什么类型,在不同类型的数据之间进行相互转换的时候,犯愁了,不知道怎么样转换才合法,怎么样转换数据才能正常?
在一小节,我们就来剖析一下我们常见的数据类型。
其实,我们没有必要关心那么多数据类型的,只要知道,数据类型就是定义数据的大小,这一句就足够了:
BYTE就是一个字节的大小,如上图中9A就是一个BYTE类型的数据,
int ,DWORD就是两个字节的大小,如上图中849A就是个DWORD或者int类型的数据
其它更大的类型(如INT64 等)……
以后,在编程的时候,当我们需要进行类型转换的时候,只要知道,小的数据类别往大数据类别上转换没有问题,反过来由于内存分配的空间不够就会导致数据丢失,精确度不高等问题!
下面我们来看一下小数(浮点类型:float)在内存里的表示方法:

大家看到,这个表示的数据,貌似不是小数啊,而且这个数据,跟上面图中的数据没有什么区别啊,都是一个模样……
让我们在换个视图,在OD的数据区右击,选择float,如下图:
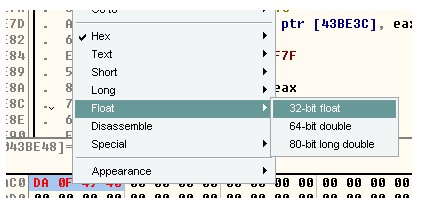
数据变成这个样子了:

哈哈,这样就清楚了,我们的数据是圆周率…(至于小数与十六进制转换的问题,大家可以自行百度,这里不做具体讲解)。
到这里,我们就又知道数据类型的另一个作用:数据类型就是规定数据的表现形式,同样的内存数据,它可以是一个整数也可以是一个小数,甚至是一个字母或者汉字……
为了证明这一点,我们再说一下字符,汉字等的概念:
就像大家如上面的小数中看到的一样,其实电脑远没有人脑智能,它根本不认识什么小数,什么字符什么整数,它认识的只是1和0这两个数,其它的它都不认识,因此我们说的字母,标点符号,汉字等等也都是一样的,其实在计算机的世界里,大家看到的那些文字,其实都是写数字,只不过是因为数据类型的特性让它显示成了汉字,字母等。如下图:
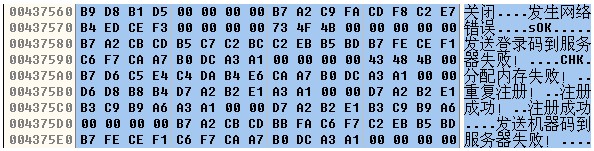
如上图,其实,大家可以看到“关闭”的文字,其实它的数据在内存中被表示成了:B9 D8 B1 D5。
如果大家以DWORD形式读出来,数据就是0xD5B1D8B9,一个很大的数字!
看到上图中的“sOK”这三个字母了吗?他们的数据就是73 4F 4B,如果大家有ASCII表的话,一查就能知道,由此可见,其实,电脑识别字母也好,识别汉字也好,其实都是根据表硬转换过来的,随便一个数据,他都能转换,顺利的话,转换出来的就是我们能识别的汉字,不顺利的话,转换出来的就是一堆乱码……
如果细心的朋友,可能发现一个问题,我们说:数据类型决定了数据的大小和表现形式,那一个字符串怎么规定大小啊?难道还有4个字节大小的字符串,12个字节大小的字符串类型?
哈哈,其实,字符串就是一个连续的BYTE(或者char)类型的数据串,由于字符串可大可小,不可以具体规定它有多大,所以大家都规定,字符串以0结尾,如果要从内存里将数据以一个字符串的形式读出来的话,那程序就是从字符串的第一个字符开始,一直读到0 处,算做读取完毕。
2.字符编码问题。
既然提到汉字,就不能不提Unicode编码,很多的同学对这个编码问题很是迷茫,总是把这个跟数据类型混淆在一起,所以我就把这两个问题放在一起说了。
其实,关于字符编码,我们在日常使用电脑是会经常遇到,应该说,我们对它是不陌生的,举个简单的例子:
我们在用IE浏览器访问国外站点时,经常会出现乱码,比如在访问一些俄语,阿拉伯语等站点时,我们经常会像下图这样切换编码方式以便别看到乱码:
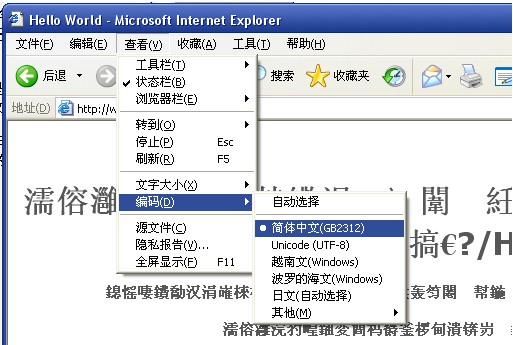
不多废话,我们进入正题。
林子大了,什么鸟都有,一样,这个世界大了,用什么语言的人都有,无奈,计算机是有说英语的人发明的,他们在考虑计算机里面字符编码的时候,只考虑到英语用到的字符,感觉一些字符占一个字节足够,也没有考虑过像中国,韩国,日本及东南亚等国的汉字录入问题(感觉跟90年代时的千年虫问题归根同源~),很多的字符都不能正常的在计算机中存放,于是便有了Unicode编码,由于原先多字节(BYTE为单位)不够表示这么多的宽字符。
因此,大家就规定Unicode编码以(WORD)为单位,存放数据,这样每个字符就大了一倍的空间来表示字符数据,表示的范围也就大了很多,由下面的一个图来说明一下他们的区别吧:
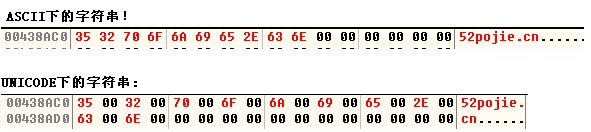
发现他们的区别了吗?中间多了很多的00,就这点区别,剩下的该是ASCII编码表转换还是这样转换的,没变!
到这里,或许又有朋友郁闷了,35 00 32 00 中间有0了,结束了,那字符还怎么能正常的读啊,这不是冲突吗?再说,3500,跟35区别很大的,怎么都能表示“5”这个字符 ???
呵呵,按照我们在本文开头将的内存数据的存储方式中Little Endian方式的高高低低原则来读取这些字符,以WORD为单位来转换一下这些数据,就变成了:0035 0032 0070 …… ,实质上就如同,1与01的区别一样,没有区别,唯一的区别就是表示的范围大了……
由于在Unicode方式下,原先在多字节方式下占一个字节的字符都变成了占两个字节,所以,单纯的00 在Unicode方式变成了 00 00 ,自然的,Unicode的字符串都是以 00 00 结尾的,这下什么就都清楚了吧!
当然,如果仔细想下。Unicode下的普通英文字符中间都被0隔开了呀,0是asc编码下字符串的结束符啊,电脑是怎么区别asc和Unicode编码的呀。由此,就要引出下一个问题:Unicode编码下的字符数据类型。
为了减少篇幅,这里只讲述一个技巧:如果字符类型的关键字中包含‘W’那就差不多应该是Unicode编码的数据类型,比如WCHAR, wchar_t等等。(具体内容,建议参看:《Windows via C/C++》[Fifth Edition]:Chapter 2: Working with Characters and Strings)
3.数据类型的小结
数据类型:就是定义数据的大小,和数据表现形式的一个规定,或者说一个模板,根据这个模板我们可以生成更多符合这个模板的数据!一般的,数据类型有两种特性,一个是它的属性,一个是它的方法(也就是动作)。
我们拿字符串这个数据类型来讲:
字符串的属性有:
a)字符串的大小(有多少个字符组成)
b)字符串的结尾标志(0)
字符串的方法(也就是动作)有:
a)将十六进制的数据转换成字符的形式显示的控制台上.
推而广之,我们现在所讲的什么面向对象变成,什么类,对象的概念,其实在像C之类面向过程的编程中已经应用到了,在C++中只是把这些做了个升级,让我们来做了数据类型定义的工作,所谓的类,对象等其实就是数据类型和变量,换了个名字而已……
在这里,或许有的朋友不明白,属性和方法是什么概念,其实通俗点讲,属性就是变量,方法就是函数,这个我会在后面的文章中详细讲述,由于我们还有学到编程相关的知识,这里暂不描述!
下面进入我们的下一节,变量的使用。
三、变量的定义和使用方法
1.什么是变量。
估计大家都知道,我们程序访问的数据一般的都是存放在内存或者寄存器中。自然的,如上次课所讲的那些数据也都是存放在内存中的,那我们在程序中,如何使用这些内存空间呢?这就有了“变量”的概念。如下图:

这里的00438400就是一个变量~,如果以一个字节的方式来读的话,它是一个BYTE类型的变量,它的内容是0xA1,00438401的内容就是0xA5,如果以WORD类型来读的话,00438400的内容是0xA5A1,如果以DWORD类型来读的话,00438400的内容是0x0000A5A1,想必经过上节的学习,我们已经能够理解这些概念了!
那变量的含义也就很清楚了,变量就是内存地址。学过编程的可能觉得不理解,编程高手可能就笑我不求甚解了,所以,如果我有什么理解不对的,不深刻的,还请各位大牛指教!
稍微熟悉点程序的人,应该知道,我们的程序被分成了代码段,数据段,资源段,堆栈段等等……
上面我们说到过 变量就是地址,那反过来说,地址就是变量,似乎也是成立的!
比如: 我们的程序代码是写在内存里的,也就是说,我们的代码也可以当作变量来使用!
想想我们写程序,不就是用代码通过变量来操作数据吗?我们写的程序本身就是在内存里放着的,代码的每个字节都有一个虚拟地址与它对应,也就是说,我们的代码本身就是一些数据。
从这里来看,似乎高手们讲的什么钩子,代码自变形,甚至我们的代码是可以放在数据区执行的等等技术,似乎也不是什么谣不可及的……
想必,大家对普通的变量应该有一定的认识了,这里呢,我就给出变量在C语言中的声明和表示方法!
2.变量的定义和使用方法。
在C语言中,我们的变量声明格式是:
数据类型 变量名;
或者
数据类型 变量名 = 常量;//常量就是一个具体的数值!
例如:
- 数据类型 变量名[元素个数];
- 或者
- 数据类型 变量名[元素个数可以留空] = {常量, [常量2|…]}; //常量就是一个具体的数值!
比如:
- 00401008 |.68 30604000 push 00406030 ; |Text = "52pojie.cn"
这里的00406030 就是字符串52pojie.cn的首个地址,那EAX中的是什么内容啊?应该也是地址吧~~~?
我们看一下0x0040603C中的内容,也就是EAX的内容:0x00406040,再看一下0x00406040中的内容,很容易的发现,原来是“Null”,奇特吧~~~
这个就是我们C语言中说到的指针的概念,很多没有好好学C语言的朋友可能都迷糊指针的概念,我们通过这个例子就应该可以很容易的明白,指针就是存放变量的地址的变量
或者直接说指针就是地址!
指针在C语言中的表示就是*,在汇编语言中的表示就是[],至于为什么要有指针,指针到底有什么作用,在写程序的过程中,指针的功能到底应该怎么使用,我会在以后的指针的课题中详细介绍!
下面讲一下结构体。
如果说,数组是一串连续的相同类型数据的序列,那结构体就可以理解为一串连续的不同类型的数据的序列。
在C语言中,定义结构体的语法格式是:
- struct 结构体名称
- {
- 基础类型1 成员变量名1;
- 基础类型2 成员变量名2;
- ……
- }结构体变量名01, 结构体变量名02…;
复制代码
在实际使用的过程中,我们一般用typedef关键字来定义结构体类型(自定义数据类型),然后使用我们自己定义的数据类型来声明结构体变量,这样使用起来更加条例,比如:
- typedef struct _GAME_OBJECT_INFO
- {
- DWORD UnKnown1[15]; // 未知 offset 0
- float fX; // X坐标 offset 0x3C
- float fZ; // Z坐标 offset 0x40
- float fY; // Y坐标 offset 0x44
- DWORD UnKnown2[55]; // 未知 offset 0x48
- DWORD dwSID; // 怪物ID offset 0x124
- DWORD UnKnown3[78]; // 未知 offset 0x128
- wchar_t *wszName; // 名字 offset 0x260
- }GAME_OBJECT_INFO, *PGAME_OBJECT_INFO;
复制代码
这样我们就很容易的定义了两个游戏对象信息的数据类型,在使用这个类型来声明这个结构体的变量就很合规矩了。如下:
- GAME_OBJECT_INFO Goi; // 声明一个结构体变量
- PGAME_OBJECT_INFO pGOI = NULL; // 声明一个结构体指针
- RtlZeroMemory(pGOI, sizeof(GAME_OBJECT_INFO)); // 给结构体指针初始化。
复制代码
当然,在现在版本的C++中,它支持在结构体中使用函数(允许结构体中有成员函数),也就是说,结构体可以当做类来直接使用,深入的研究结构体可以弄明白现在C++中一些类的基础概念,为了节省篇幅,我就不再这里牢骚了。
四、结束语
本文讲述了很多的东西,很杂,而且几乎都不是很深入,我的表述能力有限,我自认为是用我认为最普通的方式,讲述这些东西了,肯定还有很多的同学不明白我讲了写什么,我也深知我没有能力讲述更基础的教程了,就写到这里,希望大家能先看基础的一些C/C++教程,然后再参考本文,以加深理解,也避免我文中错误的理解误导大家。
本文中肯定存在很多的错误,希望大家能多多指教 | 





 雷达卡
雷达卡


.gif)
 发表于 2011-1-30 10:55
发表于 2011-1-30 10:55
 提升卡
提升卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 抢沙发
抢沙发 显身卡
显身卡

